정규표현식- Regular Expression

정규표현식
정규표현식은 문자열을 처리하는 방법 중 하나로 특정한 조건의 문자를 ‘검색’하거나 ‘치환’하는 과정을 매우 간편하게 처리 할 수 있는 수단입니다.
정규표현식 패턴들
Page 1
닫기
정규표현식은 대소문자를 구분합니다. 따라서 Case1의 정규표현식은 특정한 문자를 찾아내지만, Case2는 그렇지 못합니다.
Source : Hello world!
Case1
| Regular Expression | Hello |
|---|---|
| First match | Hello, world! |
| All match | Hello, world! |
Case2
| Regular Expression | hello |
|---|---|
| First match | Hello, world |
| All match | Hello, world |
Page 2
정규표현식은 공백을 구별합니다. 따라서 Case1의 정규표현식은 특정한 문자를 찾아내지만, Case2는 그렇지 못합니다.
Source : Hello, world!
Case1
| Regular Expression | Hello, world |
|---|---|
| First match | Hello, world! |
| All match | Hello, world! |
Case2
| Regular Expression | Hello, world |
|---|---|
| First match | Hello, world |
| All match | Hello, world |
정규표현식 패턴들
Page 3
특정한 기호는 특정한 의미를 갖습니다. 소스가 who is who일때, who로 시작하는 소스를 검출할때 ^who를 사용합니다.
who$는 who로 끝나는 텍스트를 검출합니다.
Source : who is who
Case1
| Regular Expression | ^who |
|---|---|
| First match | who is who |
| All match | who is who |
Case2
| Regular Expression | who$ |
|---|---|
| First match | who is who |
| All match | who is who |
Page 4
^와 $를 통해 문자를 검출하는 패턴을 Page3에서 알아봤는데, Page4에서는 만약 소스에 $와 ^가 포함되있을 때 어떻게 검출할수있을지를 알아봅시다.
Source : $12$\-\ $25$
Case1
| Regular Expression | ^$ |
|---|---|
| First match | $12$\-\ $25$ |
| All match | $12$\-\ $25$ |
$로 시작하는 텍스트를 검출하고싶지만, Page3에서 알아봤듯이, $ 또한, 특정한 기호이기 때문에 검출되지않습니다.
Case2
| Regular Expression | $ |
|---|---|
| First match | $12$\-\ $25$ |
| All match | $12$\-\ $25$ |
\ 는 \뒤의 기호가 정규표현식에서의 기호가 아닌 단순한 문자를 나타냅니다. 따라서 $에서 $는 단순한 문자 $입니다.
Case3
| Regular Expression | ^$ |
|---|---|
| First match | $12$ -\ $25$ |
| All match | $12$ -\ $25$ |
따라서 ^\$는 $로 시작하는 텍스트만을 검출합니다.
위에서 본 \가 하는 특정한 역할을 해제시키는 역할을 escape라고 합니다.
Case4
| Regular Expression | $$ |
|---|---|
| First match | $12$ -\ $25$ |
| All match | $12$ -\ $25$ |
마찬가지로 \$$는 \$를 통해 표현된 문자 $를 마지막으로 갖는 텍스트를 검출합니다.
Page 11
Quantifier에 대해 알아봅시다. Quantifier를 우리말로 하면 수량자라는 뜻입니다.
수량자는 어떠한 패턴이 얼마나 등장하는 가, 숫자를 나타냅니다.
수량자는 크게 *, +, ? 로 세가지가 있습니다.
* : 0개~여러개
+ : 1개~여러개
? : 0개~1개
Source : aabc abc bc
Case1
| Regular Expression | a*b |
|---|---|
| First match | aabc abc bc |
| All match | aabc abc bc |
a*b 는 b 앞의 a가 0개~여러개를 검출합니다. 따라서 a가 2개인 aab , a가 1개인 ab, a가 0개인 b 모두 검출됩니다.
Case2
| Regular Expression | a+b |
|---|---|
| First match | aabc abc bc |
| All match | aabc abc bc |
a+b 는 b 앞의 a가 1개~여러개를 검출합니다. 따라서 a가 2개인 aab , a가 1개인 ab가 검출됩니다. bc는 a가 없으니 검출되지않습니다.
Case3
| Regular Expression | a?b |
|---|---|
| First match | aabc abc bc |
| All match | aabc abc bc |
a?b 는 b 앞의 a가 0개~1개를 검출합니다. 따라서 a가 1개인 ab, a가 0개인 b가 검출됩니다. aabc는 a가 두개이므로 앞에 있는 a를 제외하고 ab가 검출됩니다.
Page 12
12 페이지에선, *와 함께 기호를 쓰는 특수한 경우를 예시를 통해 알아봅시다.
Source : -@- ** – “*” – ** -@-
Case1
| Regular Expression | .* |
|---|---|
| First match | -@- ** – “*” – ** -@- |
| All match | -@- ** – “*” – ** -@- |
*은 * 앞의 문자를 0개~여러개를 함께 검출하고, .은 모든 특성을 포함하기때문에 .*은 모두 검출합니다.
Case2
| Regular Expression | -A*- |
|---|---|
| First match | -@- ** – “*” – ** -@- |
| All match | -@- ** – “*” – ** -@- |
-A*-는 -와 - 사이에 A가 0개~여러개가 포함되는 것을 검출합니다. 따라서 –는 -와 -사이에 A가 0개이므로 검출되고
-@-는 -와 -사이에 A가 아닌 @가 포함돼기에 검출되지않습니다.
Case3
| Regular Expression | [-@]* |
|---|---|
| First match | -@- ** – “*” – ** -@- |
| All match | -@- ** – “*” – ** -@- |
[-@]*는 대괄호 안의 -와 @가 둘 중 하나가 있는 것을 검출하고, [-@]*은 [-@]가 하나의 문자로 [-@]가 0개~여러개를 검출합니다.
따라서 위와 같이 검출합니다.
Page 13
13 페이지에선, +와 함께 기호를 쓰는 특수한 경우를 예시를 통해 알아봅시다.
Source : -@@@- * ** - - “*” – * ** -@@@-
Case1
| Regular Expression | *+ |
|---|---|
| First match | -@@@- * ** - - “*” – * ** -@@@- |
| All match | -@@@- * ** - - “*” – * ** -@@@- |
*+ 는 \를 통해 문자 *를 검출하고, +를 통해 문자 *를 1개~여러개 검출합니다
Case2
| Regular Expression | -@+- |
|---|---|
| First match | -@@@- * ** - - “*” – * ** -@@@- |
| All match | -@@@- * ** - - “*” – * ** -@@@- |
-@+- 는 -와 -사이에 @가 1개 이상을 검출합니다. 따라서 -@@@-를 검출합니다.
Case3
| Regular Expression | [^ ]+ |
|---|---|
| First match | -@@@- * ** - - “*” – * ** -@@@- |
| All match | -@@@- * ** - - “*” – * ** -@@@- |
[^ ]+ 에서 [^ ]는 ^가 공백을 부정하므로 공백이 아닌 텍스트 전부를 검출합니다.
Page 14
14 페이지에선, ?와 함께 기호를 쓰는 특수한 경우를 예시를 통해 알아봅시다.
Source : –XX-@-XX-@@-XX-@@@-XX-@@@@-XX-@@-@@-
Case1
| Regular Expression | -X?XX?X |
|---|---|
| First match | –XX-@-XX-@@-XX-@@@-XX-@@@@-XX-@@-@@- |
| All match | –XX-@-XX-@@-XX-@@@-XX-@@@@-XX-@@-@@- |
-X?XX?X 는 - 뒤에 XX를 포함하고 XX 앞, 뒤로 X가 0개 또는 1개를 검출합니다.
검출할 수 있는 텍스트로는 -XX,-XXX,-XXXX가 있습니다.
따라서 -XX는 XX만 포함하고 앞 뒤로 X가 0개이므로 검출합니다.
Case2
| Regular Expression | -@?@?@?- |
|---|---|
| First match | –XX-@-XX-@@-XX-@@@-XX-@@@@-XX-@@-@@- |
| All match | –XX-@-XX-@@-XX-@@@-XX-@@@@-XX-@@-@@- |
-@?@?@?- 는 -와 - 사이에 @가 0개 또는 1개를 검출합니다. 같은 패턴이 3개있으므로,
따라서 검출할 수 있는 텍스트로는 –, -@-, -@@-, -@@@- 가 있습니다.
Case3
| Regular Expression | [^@]@?@ |
|---|---|
| First match | –XX-@-XX-@@-XX-@@@-XX-@@@@-XX-@@-@@- |
| All match | –XX-@-XX-@@-XX-@@@-XX-@@@@-XX-@@-@@- |
[^@]@?@는 [^@]는 @가 아닌 것이고, @?는 @ 0개 또는 1개를 검출합니다.
-@는 -가 @ 아닌 것이고, @?가 0개를 나타내고, 뒤 @가 붙은 것이기때문에 검출합니다.
Page 15
15 페이지에선, 수량을 정확하게 설정하는 수량자를 알아봅시다.
정확한 수량을 설정하는 수량자는 기호 { }를 사용합니다.
예시를 통해 알아봅시다.
Source : One ring to bring them all and in the darkness bind them
Case1
| Regular Expression | .{5} |
|---|---|
| First match | One ring to bring them all and in the darkness bind them |
| All match | One ring to bring them all and in the darkness bind them |
.{5}는 5개의 문자를 검출합니다. 따라서 First match에서 One r 을 검출하고One r/ing t/o bri/ng th/em al/l and/ in t/he da/rknes/s bin/d the///m이므로 마지막 m을 제외하고 검출합니다.
Case2
| Regular Expression | [els]{1,3} |
|---|---|
| First match | One ring to bring them all and in the darkness bind them |
| All match | One ring to bring them all and in the darkness bind them |
[els]{1,3}은 e,l,s을 검출하돼 길이가 1이상 3이하를 검출합니다.
Case3
| Regular Expression | [a-z]{3,} |
|---|---|
| First match | One ring to bring them all and in the darkness bind them |
| All match | One ring to bring them all and in the darkness bind them |
[a-z]{3,}는 소문자로 시작하는 것 중 길이가 3이상인 것을 검출합니다.
따라서 One 은 대문자로 시작하기 때문에, to와 in은 길이가 2이기때문에 검출하지않습니다.
Page 16
16 페이지에선 앞서 배운 *, +, ? 을 중괄호로 표현해봅시다.
+는 0이상이기때문에, {0,}와 같습니다.
*는 1이상이기때문에, {1,}와 같습니다.
?는 0또는 1이기때문에, {0,1}와 같습니다.
Page 17
17 페이지에선 수량자 뒤에 ?가 들어갔을때를 알아봅시다.
예시를 통해 알아봅시다.
Source : One ring to bring them all and in the darkness bind them
Case1
| Regular Expression | r.* |
|---|---|
| First match | One ring to bring them all and in the darkness bind them |
| All match | One ring to bring them all and in the darkness bind them |
r.*는 앞서봤던 것 처럼 r뒤에 모든 속성과 상관없이( . ) 길이가 0이상인 것을 검출합니다. 따라서 r로 시작해 문장 끝에서 끝납니다.
Case2
| Regular Expression | r.*? |
|---|---|
| First match | One ring to bring them all and in the darkness bind them |
| All match | One ring to bring them all and in the darkness bind them |
그러나 *뒤에 ?가 붙으면 이는 0을 나타냅니다. 따라서 r만을 검출합니다.
Case3
| Regular Expression | r.+ |
|---|---|
| First match | One ring to bring them all and in the darkness bind them |
| All match | One ring to bring them all and in the darkness bind them |
r.+ 는 r뒤에 모든 속성인 길이가 1이상을 검출합니다. 따라서 r부터 문장끝까지 검출합니다.
Case4
| Regular Expression | r.+? |
|---|---|
| First match | One ring to bring them all and in the darkness bind them |
| All match | One ring to bring them all and in the darkness bind them |
그러나 +뒤에 ?가 붙으면 이는 1을 나타냅니다. 따라서 r뒤에 문자 하나만을 붙여 검출합니다.
Case5
| Regular Expression | r.? |
|---|---|
| First match | One ring to bring them all and in the darkness bind them |
| All match | One ring to bring them all and in the darkness bind them |
r.?는 r은 r뒤에 모든 속성인 길이가 0또는 1일 검출합니다. 따라서 ri, rk를 검출합니다.
Case6
| Regular Expression | r.?? |
|---|---|
| First match | One ring to bring them all and in the darkness bind them |
| All match | One ring to bring them all and in the darkness bind them |
그러나 ?뒤에 ?가 있으면 이는 0을 나타냅니다. 따라서 r만을 검출합니다.
수량자 뒤에 ?가 붙으면 이는 공통적으로 원래 수량자가 택할 수 있는 수량 중 최소를 택합니다.
이처럼 하는 이유를 알아봅시다.
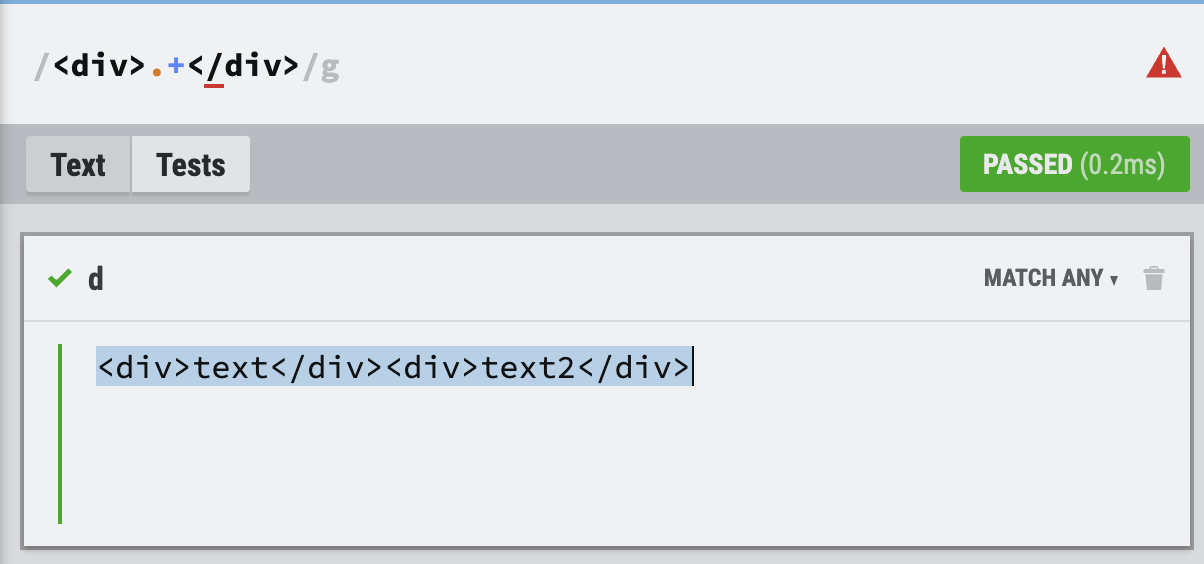
위처럼 div를 택할때 .+의 기호를 택한다면 <div>와 </div>안의 하나 이상을 택하는 것인데,
를 택하는 것이 아닌, text의 <div>와 text2의 </div>를 택하여 통으로 검출합니다.
이를 탐욕적인 수량자(Greedy Quantifier)라고 합니다.
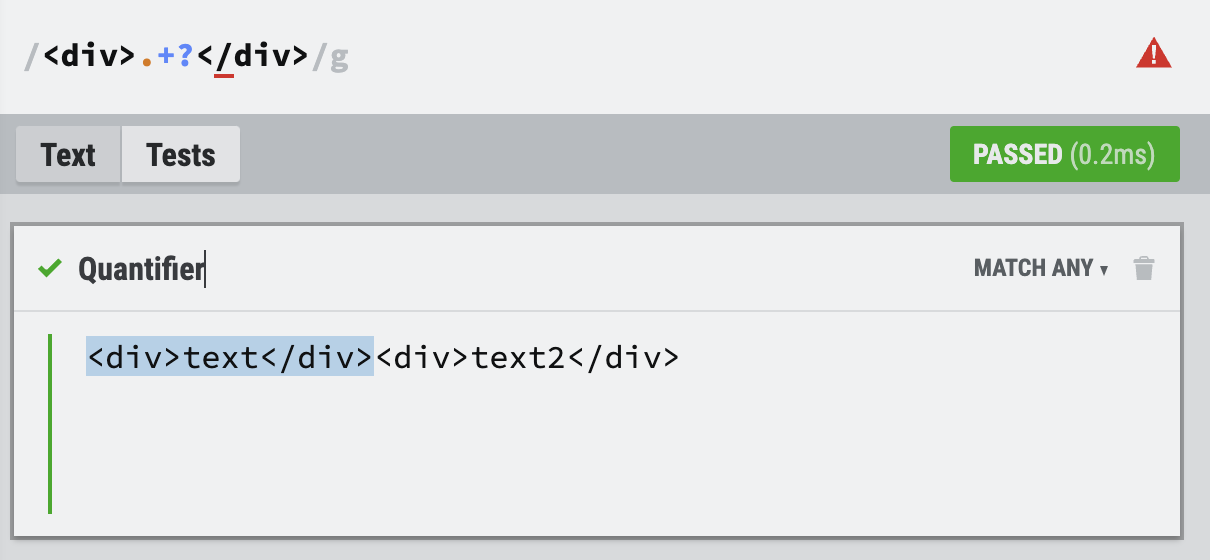
이를 앞의 <div>text</div>만을 택하여 검출을 하기위해선,
앞서 했던것처럼 .+?를 한다면 하나씩 체크할 수 있습니다.
이를 게으른 수량자(Lazy Quantifier)라고 합니다.
Page 18
18 페이지에선 \w 에 대해 알아봅시다. w는 word, 즉 단어의 줄임말입니다. 모든 문자와 _을 검출합니다.
따라서 \w 는 [A-z0-9_]와 정확히 일치합니다.
Source : A1 B2 c3 d_4 e:5 ffGG77–__–
Case1
| Regular Expression | \w |
|---|---|
| First match | A1 B2 c3 d_4 e:5 ffGG77–__– |
| All match | A1 B2 c3 d_4 e:5 ffGG77–__– |
공백과 _을 제외한 기호는 word에 제외되기 때문에 검출되지않습니다.
Case2
| Regular Expression | \w* |
|---|---|
| First match | A1 B2 c3 d_4 e:5 ffGG77–__– |
| All match | A1 B2 c3 d_4 e:5 ffGG77–__– |
*은 0개 이상을 검출하기 때문에 First match 에서 A1을 검출합니다.
Case2
| Regular Expression | [a-z]\w* |
|---|---|
| First match | A1 B2 c3 d_4 e:5 ffGG77–__– |
| All match | A1 B2 c3 d_4 e:5 ffGG77–__– |
[a-z]\w*은 소문자로 시작하며, 그 뒤 word를 검출합니다. 따라서 대문자로 시작하는 A1, B2는 검출되지않고,
ffGG77은 소문자로 시작하기때문에 대문자가 뒤에 있어도 검출됩니다.
Case3
| Regular Expression | \w{5} |
|---|---|
| First match | A1 B2 c3 d_4 e:5 ffGG77–__– |
| All match | A1 B2 c3 d_4 e:5 ffGG77–__– |
\w 는 word이며 길이가 5인 것을 검출합니다. 따라서 길이가 5가 되지않는 A1 B2 c3 d_4 e:5 는 검출되지않습니다.
Page 19
19 페이지에선 \W 에 대해 알아봅시다. \W는 \w 와 정확히 반대입니다.
따라서 \W 는 [^A-z0-9_]와 정확히 일치합니다.
Source : AS _34:AS11.23 @#$ %12^*
Case1
| Regular Expression | \W |
|---|---|
| First match | AS _34:AS11.23 @#$ %12^* |
| All match | AS _34:AS11.23 @#$ %12^* |
\W는 공백과 _을 제외한 기호를 검출합니다.
Page 20
20페이지에선 \s와 \S에 대해 알아봅시다. \s 는 공백을 검출합니다. \S는 공백을 제외하고 검출합니다.
Source : Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago.
Case1
| Regular Expression | \s |
|---|---|
| First match | Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago. |
| All match | Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago. |
Case2
| Regular Expression | \S |
|---|---|
| First match | Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago. |
| All match | Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago. |
Page 21
21페이지에선 \d와 \D에 대해 알아봅시다. d는 digit의 줄임말입니다.
\d는 [0-9]와 일치합니다. \D는 \d를 제외하고 검출합니다.
Source : Page 123; published: 1234 id=12#24@112
Case1
| Regular Expression | \d |
|---|---|
| First match | Page 123; published: 1234 id=12#24@112 |
| All match | Page 123; published: 1234 id=12#24@112 |
Case1
| Regular Expression | \D |
|---|---|
| First match | Page 123; published: 1234 id=12#24@112 |
| All match | Page 123; published: 1234 id=12#24@112 |
Page 22
22페이지에선 \b에 대해 알아봅시다. b는 word boundary의 줄임말입니다.
\b.는 어절단위로 앞부분을, .\b는 어절단위의 뒷부분을 검출합니다.
Source : Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago.
Case1
| Regular Expression | \b. |
|---|---|
| First match | Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago. |
| All match | Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago. |
Case2
| Regular Expression | .\b |
|---|---|
| First match | Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago. |
| All match | Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago. |
Case3
| Regular Expression | \bcat |
|---|---|
| First match | cat concat |
| All match | cat concat |
Case4
| Regular Expression | cat\b |
|---|---|
| First match | cat concat |
| All match | cat concat |
Page 23
23 페이지에선 \B에 대해 알아봅시다. \B는 \b의 반대를 의미합니다.
Source : Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago.
Case1
| Regular Expression | \B. |
|---|---|
| First match | Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago. |
| All match | Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago. |
Case2
| Regular Expression | .\B |
|---|---|
| First match | Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago. |
| All match | Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago. |
Page 24
24페이지에선 \A와 \Z에 대해 알아봅시다. \A는 문장의 앞을, \Z는 문장의 뒤를 검출한다는 점에서,
\A는 ^와 유사하고, \Z는 $와 유사합니다.
Source : Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago.
Case1
| Regular Expression | \A… |
|---|---|
| First match | Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago. |
| All match | Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago. |
Case2
| Regular Expression | …\Z |
|---|---|
| First match | Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago. |
| All match | Ere iron was found or tree was hewn, When young was mountain under moon; Ere ring was made, or wrought was woe, It walked the forests long ago. |
그럼 이제 \A와 ^, \Z와 $의 차이점에 대해 알아봅시다.

\AEre는 miltiline을 적용하여도 전체의 가장 앞부분의 Ere를 검출합니다.

그러나 ^Ere는 첫번째 문장 뿐만아니라 세번째 문장또한 검출합니다.
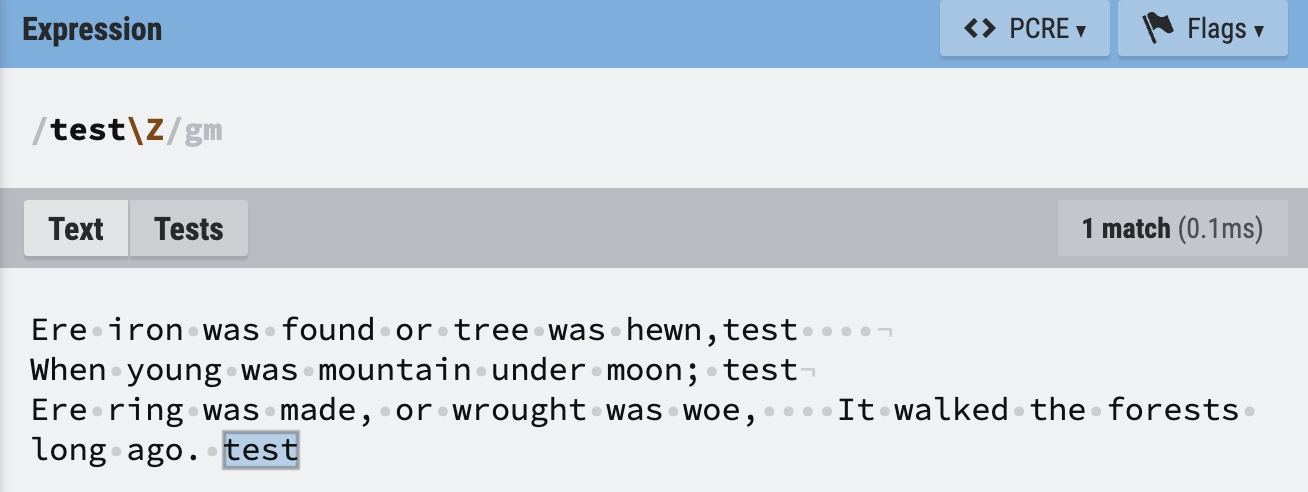
마찬가지로 \Z는 마지막 test만을 검출합니다.

test$ 또한 마찬가지로 문장 끝 test를 모두 검출합니다.
Page 25
25 페이지는 예제를 통해 자세히 알아봅시다.
Source : AAAX—aaax—111
Case1
| Regular Expression | \w+ |
|---|---|
| First match | AAAX—aaax—111 |
| All match | AAAX—aaax—111 |
\w는 문자를 뜻하고 +는 0이상을 검출하기 때문에 \w+는 위와 같이 검출합니다.
Case2
| Regular Expression | \w+(?=X) |
|---|---|
| First match | AAAX—aaax—111 |
| All match | AAAX—aaax—111 |
**여기서 (?=
AAAX—aaax—111 에서 X까지 검출하고 X는 검출되지않는 것을 볼수있습니다.
Case3
| Regular Expression | \w+(?=\w) |
|---|---|
| First match | AAAX—aaax—111 |
| All match | AAAX—aaax—111 |
마찬가지로 \w+(?=\w)는 \w 까지 검출하는 것이고, \w는 모든 문자를 뜻하기때문에 각각 마지막 문자를 제외하고 검출합니다.

추가적으로 위와같은 상황에서, AAAX에서 AAA를 검출하고, 뒤에 aaaX에서 aaa 또한 검출합니다.